The Genetic Code
Melissa Hardy
Codons specify amino acids
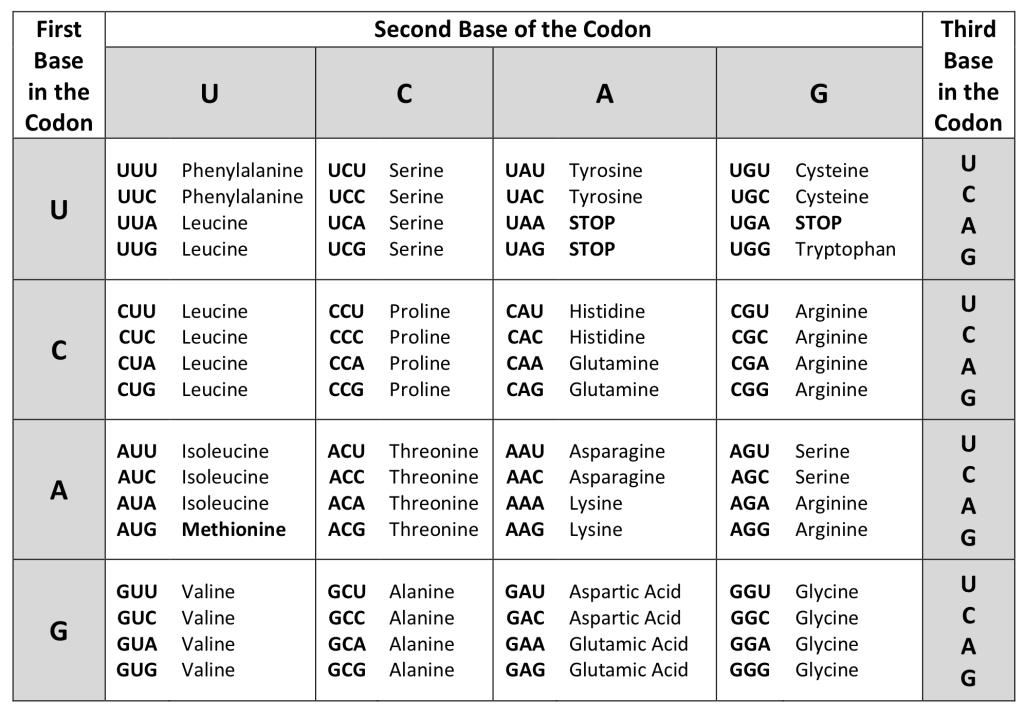
Each amino acid is defined by a three-nucleotide sequence called a triplet codon, or simply a codon. Given the different numbers of “letters” in the mRNA and protein “alphabets,” scientists theorized that single amino acids must be represented by combinations of nucleotides. Nucleotide doublets would not be sufficient to specify every amino acid because there are only 16 possible two-nucleotide combinations (42). In contrast, there are 64 possible nucleotide triplets (43), and there are 20 different amino acids encoded. Scientists theorized that amino acids were encoded by nucleotide triplets and that the genetic code was “degenerate.” In other words, a given amino acid could be encoded by more than one nucleotide triplet. This was later confirmed experimentally: Francis Crick and Sydney Brenner used the chemical mutagen proflavin to insert one, two, or three nucleotides into the gene of a virus. When one or two nucleotides were inserted early in the coding sequence, the normal proteins were not produced. When three nucleotides were inserted, the protein was synthesized and functional. This demonstrated that the amino acids must be specified by groups of three nucleotides. These nucleotide triplets are called codons. The insertion of one or two nucleotides completely changed the triplet reading frame, thereby altering the message for every subsequent amino acid. Though insertion of three nucleotides caused an extra amino acid to be inserted during translation, the integrity of the rest of the protein was maintained.
The Genetic Code Is Degenerate
In addition to codons that instruct the addition of a specific amino acid to a polypeptide chain, three of the 64 codons terminate protein synthesis and release the polypeptide from the translation machinery without the attachment of an amino acid. These triplets are called nonsense codons, or stop codons. Another codon, AUG, also has a special function. In addition to specifying the amino acid methionine, it also serves as the start codon to initiate translation. The reading frame for translation is set by the AUG start codon near the 5′ end of the mRNA. Following the start codon, the mRNA is read in groups of three until a stop codon is encountered.
The arrangement of the coding table reveals the structure of the code. There are sixteen “blocks” of codons, each specified by the first and second nucleotides of the codons within the block, e.g., the “AC*” block that corresponds to the amino acid threonine (Thr). Some blocks are divided into a pyrimidine half, in which the codon ends with U or C, and a purine half, in which the codon ends with A or G. Some amino acids get a whole block of four codons, like alanine (Ala), threonine (Thr) and proline (Pro). Some get the pyrimidine half of their block, like histidine (His) and asparagine (Asn). Others get the purine half of their block, like glutamate (Glu) and lysine (Lys). Note that some amino acids get a block and a half-block for a total of six codons.
The specification of a single amino acid by multiple similar codons is called “degeneracy.” Degeneracy is believed to be a cellular mechanism to reduce the negative impact of random mutations. Codons that specify the same amino acid typically only differ by one nucleotide. In addition, amino acids with chemically similar side chains tend to be encoded by similar codons. For example, aspartate (Asp) and glutamate (Glu), which occupy the GA* block, are both negatively charged. This nuance of the genetic code causes a single-nucleotide substitution mutation to sometimes specify the same amino acid (and therefore have no effect on protein function) or a similar amino acid (increasing the chances for the protein to retain complete or partial function).
The genetic code is nearly universal.
With a few minor exceptions, virtually all species use the same genetic code for protein synthesis. Conservation of codons means that a purified mRNA encoding the globin protein in horses could be transferred to a tulip cell, and the tulip would synthesize horse globin. That there is only one genetic code is powerful evidence that all of life on Earth evolved from a common ancestor, especially considering that there are about 1084 possible combinations of 20 amino acids and 64 triplet codons.
Media Attributions
- Genetic Code © Melissa Hardy is licensed under a Public Domain license
A duplicated chromosome cartoon is shown. A strand is shown emerging from one arm of the chromosome, which turns into many side-by-side half loops. This becomes a nucleosome, with DNA wound around many histones, which becomes DNA wound around single histones, which becomes a double helix showing the base pairs of DNA.
The top shows a sphere that is diffusely stained in many different colors. Bottom right shows condensed chromosomes as colored rod-like structures. Bottom left shows the same colored rods, but lined up and organized by chromosome pair, 1 through 23.
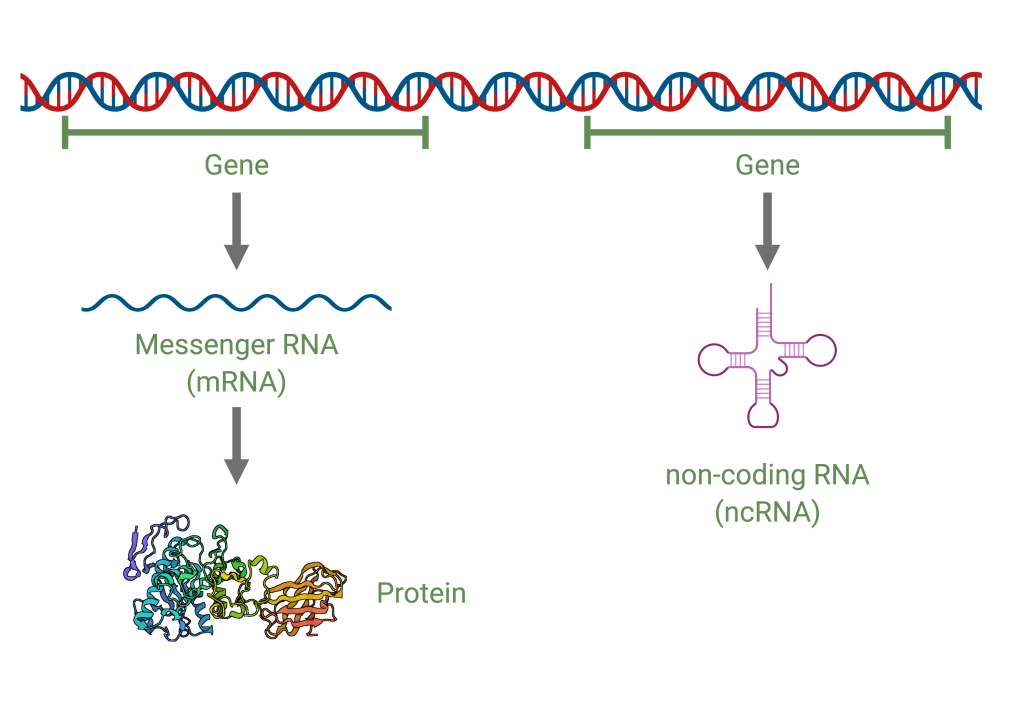
A strand of DNA is shown at top. Under are two lines, each labeled Gene. On the left, an arrow down from the word gene points to a squiggly line labeled messenger RNA (mRNA). An arrow points down to a ribbon diagram of a protein. The gene on the right points down to a secondary structure of RNA. It is labeled non-coding RNA (ncRNA).
Structural Chemist

Figure 1. A photo of Dr. Nogales with one of the machines in her lab at the University of California, Berkeley.
Dr. Eva Nogales is a Howard Hughes Medical Institute investigator, Senior Faculty Scientist at the Lawrence Berkeley National Laboratory, and Professor of Biochemistry, Molecular Biology, and Structural Biology at the University of California, Berkeley. Dr. Nogales received her PhD in Biophysics at Keele University in the United Kingdom under Dr. Joan Bordas.
Nogales’s current work at the University of California is dedicated to gaining mechanistic insight into eukaryotic biology - the central dogma of replication machinery and cytoskeleton interactions and dynamics in cellular division.Currently, Dr. Nogales and her students are investigating the complex interactions between microtubules, epigenetic regulation, and transcriptional mechanisms. The lab specializes in cryo-electron microscopy and biochemical and biophysical assays inorder to explore these subjects.
Within her lab’s investigations into microtubules, Dr. Nogales is exploring their associated proteins, the kinetochore interface, and the structural basis of their instability. Microtubules play a pivotal role in several cell processes - cell division, intracellular transport, and structural integrity of cells. Gaining insight into how microtubules function and change can unveil the intricacies of the fundamental biological mechanisms and development of therapeutic treatments for diseases such as cancer (where microtubules are often the subject of drug targeting).
Care to learn more? Visit the professors website here to read more about her current explorations, or perhaps, be a part of them.
Structural Chemist
Figure 1. A photo of Dr. Nogales with one of the commonly used machines in her lab at the University of California, Berkeley.
Dr. Eva Nogales is a Howard Hughes Medical Institute investigator, Senior Faculty Scientist at the Lawrence Berkeley National Laboratory, and Professor of Biochemistry, Molecular Biology, and Structural Biology at the University of California, Berkeley. Dr. Nogales received her PhD in Biophysics at Keele University in the United Kingdom under Dr. Joan Bordas.
Nogales’s current work at the University of California is dedicated to gaining mechanistic insight into eukaryotic biology - the central dogma of replication machinery and cytoskeleton interactions and dynamics in cellular division.Currently, Dr. Nogales and her students are investigating the complex interactions between microtubules, epigenetic regulation, and transcriptional mechanisms. The lab specializes in cryo-electron microscopy and biochemical and biophysical assays inorder to explore these subjects.
Within her lab’s investigations into microtubules, Dr. Nogales is exploring their associated proteins, the kinetochore interface, and the structural basis of their instability. Microtubules play a pivotal role in several cell processes - cell division, intracellular transport, and structural integrity of cells. Gaining insight into how microtubules function and change can unveil the intricacies of the fundamental biological mechanisms and development of therapeutic treatments for diseases such as cancer (where microtubules are often the subject of drug targeting).
Care to learn more? Visit the professors website here to read more about her current explorations, or perhaps, be a part of them.
The Genome
The cell's entire genetic content is its genome. Genomes consist of one or more chromosomes. Each chromosome is a single, double-stranded molecule of DNA. Prokaryotes generally have a single circular chromosome. Eukaryotes generally have multiple linear chromosomes that are enclosed within a membrane-bound nucleus. Each eukaryotic species has a characteristic number of chromosomes per cell. For example, humans have 46 chromosomes per cell. Eukaryotic genomes also include mitochondrial DNA and/or plastid DNA. These organelles have their own DNA because they were originally derived from free-living bacteria.
Chromatin and Chromosomes
Chromatin is the material that makes up a chromosome. It consists of DNA and proteins. The major proteins in chromatin are histone proteins, which function to package and condense the DNA molecule. Each chromosome contains one or two double-stranded DNA molecules. The word chromosome is composed of two parts: “chromo” meaning colored or stained and “some” meaning object or body. It is important to recognize that chromosome refers to a complete object. A single chromosome may contain thousands of genes.
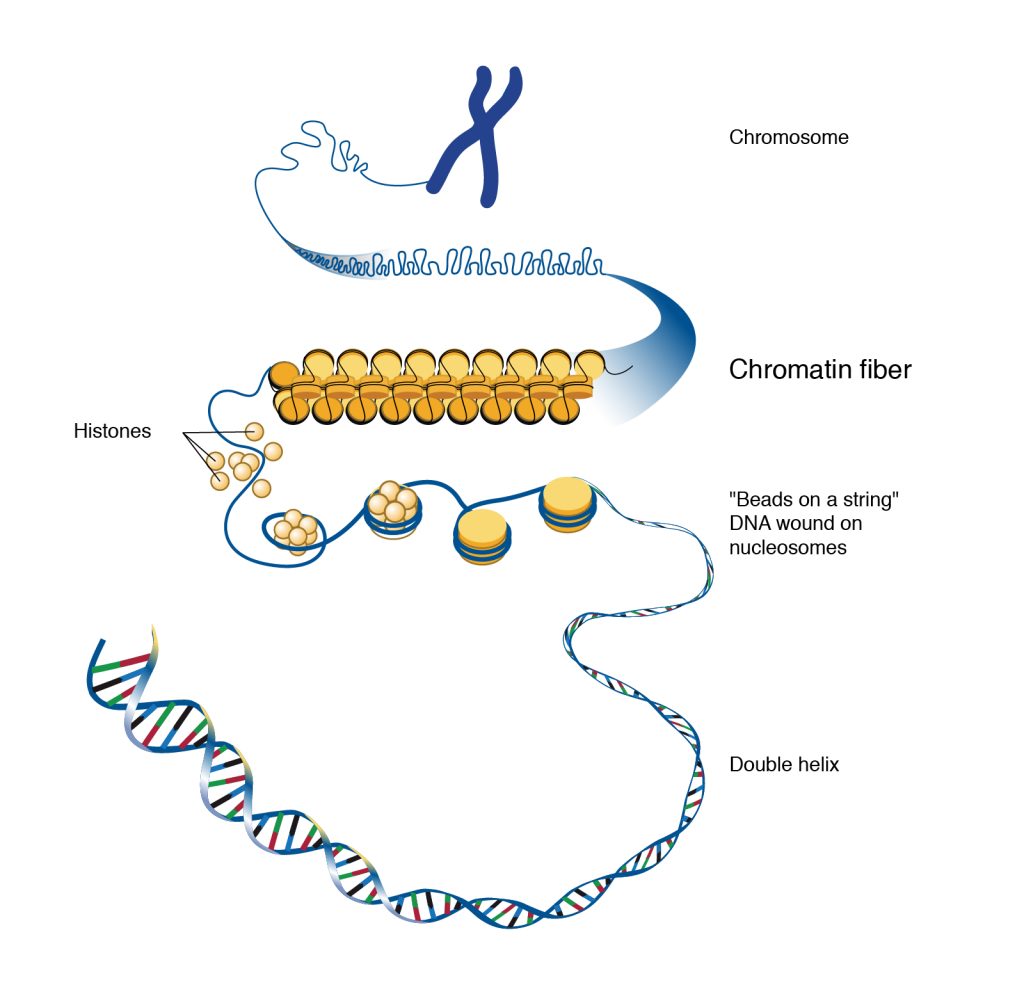
When a eukaryotic cell is actively undergoing cell division, the chromatin is tightly packaged into a compact chromosome structure. When a cell is not actively dividing, the chromatin is more relaxed and spread out so that gene expression can take place.

Genes
A gene is defined as a sequence of DNA that codes for a functional product. Many genes contain the information to make protein products. Other genes code for RNA products. On each chromosome, there are thousands of genes that are responsible for determining the genotype and phenotype of the individual. The human genome contains about 3 billion base pairs and has around 20,000 genes that code for proteins.

{kind=link}