3.4 Protein Structure and Function
Learning Objectives
By the end of this section, you will be able to do the following:
- Describe the general functions proteins perform in the cell and in tissues.
- Explain the relationship between amino acids and proteins.
Proteins are one of the most abundant organic molecules in living systems. About half of the dry weight of a cell is protein. Proteins have the most diverse range of functions of all the macromolecules. They are the main molecules that carry out the functions of the cell.
The major reason that proteins are so varied in their function is due to their ability to bind other molecules. Various proteins can bind other proteins, DNA, RNA, lipids, carbohydrates, ions, or small molecules. Proteins are specific in their binding abilities; meaning certain proteins can only bind to certain molecules. The generic name for a molecule that a protein binds is ligand, and the place on the protein where it binds is the binding site.
The ability to specifically bind other molecules is a characteristic of a protein’s shape.
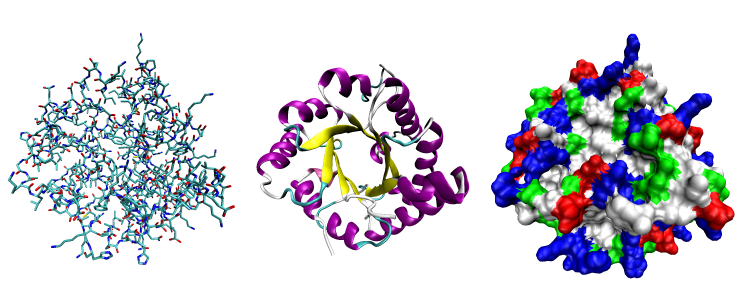
Proteins may be structural, regulatory, contractile, or protective. They may serve in transport, storage, communication, or defense; or they may be toxins or enzymes. Each cell in a living system contains thousands of different proteins, each with a unique function. Their structures, like their functions, vary greatly. Proteins are synthesized by ribosomes, which attach amino acids together to form a polypeptide, which folds into its three-dimensional shape based on the chemical properties of the amino acids and the environment in which the protein is located.
Video 3.4.1. What is a Protein? (from PDB-101) by RCSBProteinDataBank
Amino Acids
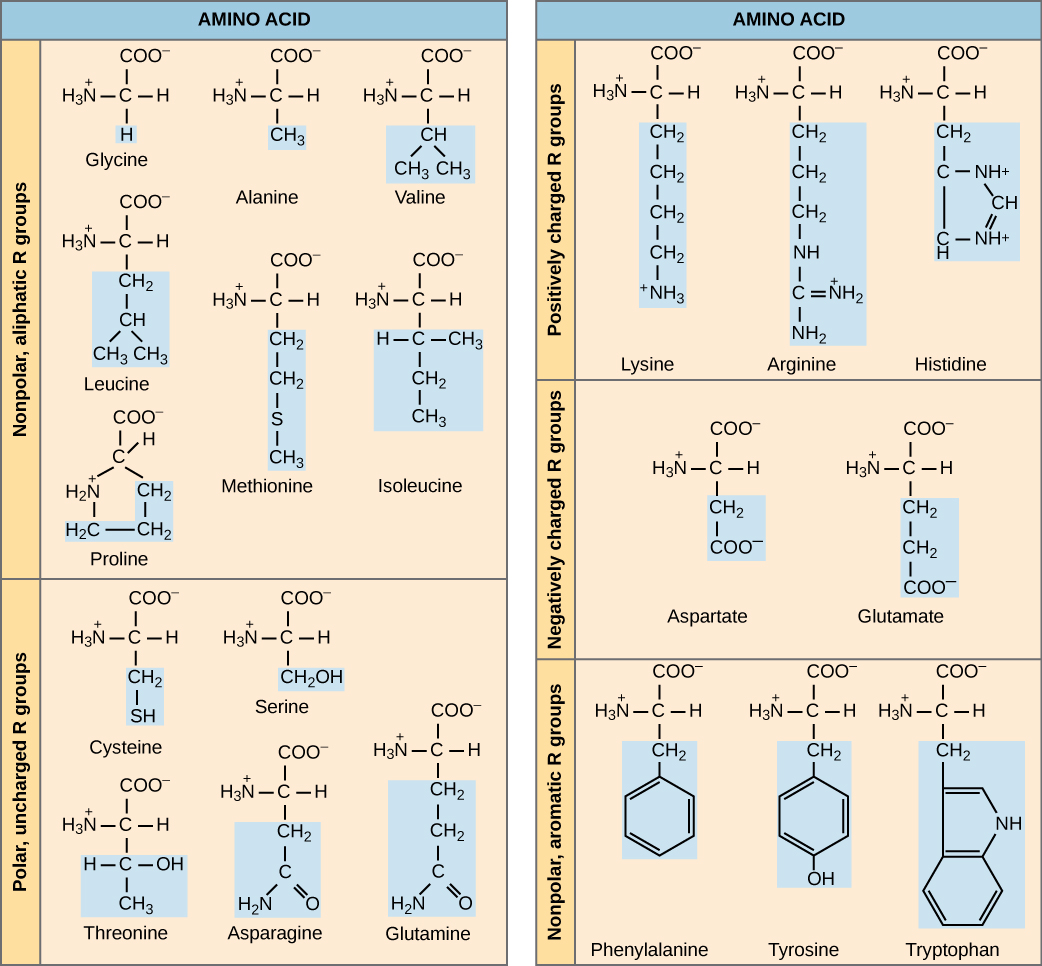
Amino acids are the monomers that comprise proteins. There are 20 common amino acids present in proteins. Each amino acid has the same fundamental structure, which consists of a central carbon atom, or the alpha (α) carbon, bonded to an amino group (NH2), a carboxyl group (COOH), and to a hydrogen atom. Every amino acid also has another atom or group of atoms bonded to the central atom, which is known as the R group.
We use the name “amino acid” because they contain both an amino group and a carboxyl group (which is acidic) in their structure. For each of the 20 amino acids, the R group (or side chain) is different.
The chemical nature of the side chain determines the amino acid’s nature (that is, whether it is charged, polar, or nonpolar). For example, the amino acid glycine has a hydrogen atom as the R group. A single upper case letter or a three-letter abbreviation is used to represent each amino acid. For example, the letter V or the three-letter symbol Val represents valine.
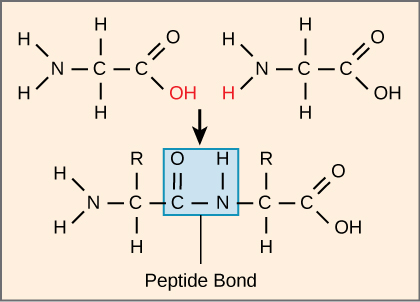
The sequence and the number of amino acids ultimately determine the protein’s shape, size, and function. A covalent bond, or peptide bond, attaches to each amino acid, which a dehydration reaction forms. One amino acid’s carboxyl group and the incoming amino acid’s amino group combine, releasing a water molecule. The resulting bond is the peptide bond.
The products that such linkages form are peptides. As more amino acids join to this growing chain, the resulting chain is a polypeptide. Each polypeptide has a free amino group at one end. This end the N terminal, carboxylor the amino terminal, and the other end has a free carboxyl group, also the C or carboxyl terminal. While the terms polypeptide and protein are sometimes used interchangeably, a polypeptide is technically a polymer of amino acids, whereas the term protein is used for a polypeptide or polypeptides that have combined together, often have bound non-peptide prosthetic groups, have a distinct shape, and have a unique function.
Nine of these are essential amino acids in humans because we need them to build proteins, but the human body cannot produce them. We therefore must obtain them from our diet. Which amino acids are essential varies from organism to organism.
Video 3.4.2. Scientific animation: protein production and folding by Spronk Studio
Practice Questions
Glossary
amino acid
a protein’s monomer; has a central carbon or alpha carbon to which an amino group, a carboxyl group, a hydrogen, and an R group or side chain is attached; the R group is different for all 20 common amino acids
peptide bond
bond formed between two amino acids by a dehydration reaction
polypeptide
long chain of amino acids linked by peptide bonds
Figure Descriptions
Figure 3.4.1. The image showcases three distinct visualizations of a protein’s three-dimensional structure, displayed from left to right. On the left is the all-atom representation, depicting an intricate tangle of lines and sticks, each representing different atoms, and they’re colored variably in shades of blue, red, and black. This view highlights the intricate connections between atoms. In the center is the ribbon diagram, illustrating regions of secondary structure with smooth curves; alpha-helices appear in purple and beta-sheets in yellow, wrapped around and interacting with each other elegantly. On the right is the surface representation, which is densely packed with a mosaic of colors. The colors correspond to the chemical properties of amino acids: nonpolar regions in white, polar regions in green, acidic regions in red, and basic regions in blue. [Return to Figure 3.4,1]
Figure 3.4.2. The diagram is a two-column table titled “AMINO ACID,” dividing the twenty standard amino acids into five chemical categories. In the left column, the upper section lists the non-polar, aliphatic R-group amino acids—glycine, alanine, valine, leucine, methionine, isoleucine, and proline—while the lower section displays the polar, uncharged R-group amino acids—cysteine, serine, threonine, asparagine, and glutamine. In the right column, the top section contains the positively charged R-group amino acids—lysine, arginine, and histidine; the middle section shows the negatively charged R-group amino acids—aspartate and glutamate; and the bottom section features the non-polar, aromatic R-group amino acids—phenylalanine, tyrosine, and tryptophan. Each amino acid is drawn with the standard backbone (amino group, central α-carbon, and carboxylate) in black, while its distinctive side chain (R group) is shaded in light blue, making the chemical differences among categories immediately apparent and underscoring that proteins derive their diversity from twenty amino acids whose side chains vary in polarity, charge, or hydrophobic character. [Return to Figure 3.4.2]
Figure 3.4.3. The schematic shows two generic amino acids positioned side-by-side: each has an amino group on the left, a central carbon with an “R” side chain, and a carboxyl group on the right. The carboxyl carbon of the left amino acid and the amino nitrogen of the right amino acid are highlighted in red, specifically the hydroxyl (‒OH) from the carboxyl group and a hydrogen (H) from the amino group, indicating the atoms that will be removed as water (H₂O). A downward arrow leads to a combined molecule where the two residues are now linked; a blue rectangle encloses the new carbonyl-carbon-to-nitrogen linkage, labelled “Peptide Bond.” This one-step visual emphasizes that peptide bonds form through dehydration synthesis: the condensation of a carboxyl group and an amino group releases water and connects successive amino acids in a polypeptide chain. [Return to Figure 3.4.3]
Licenses and Attributions
“3.4 Protein Structure Function” is adapted from “3.4 Proteins” by Mary Ann Clark, Matthew Douglas, and Jung Choi for OpenStax Biology 2e under CC-BY 4.0. “3.4 Protein Structure Function” is licensed under CC-BY-NC 4.0.
Media Attributions
- Protein shape © Opabinia regalis is licensed under a CC BY-SA (Attribution ShareAlike) license
- amino acid © OpenStax is licensed under a CC BY (Attribution) license
- peptide bond © OpenStax is licensed under a CC BY (Attribution) license
biological macromolecule made up of amino acids; essential for cellular function.
molecule produced by a signaling cell that binds with a specific receptor, delivering a signal in the process
the place on the protein where it binds
cellular structure that carries out protein synthesis
a protein's monomer; has a central carbon or alpha carbon to which an amino group, a carboxyl group, a hydrogen, and an R group or side chain is attached; the R group is different for all 20 common amino acids
one of the two key functional groups bonded to the α‑carbon (central carbon) in an amino acid. In the standard structure, an amino acid carries both an amino group (–NH₂) and a carboxyl group (–COOH) attached to the same carbon, along with a hydrogen atom and a variable R group that defines each amino acid’s identity
the acidic functional group made of a carbon double-bonded to one oxygen and single-bonded to a hydroxyl (–OH), written –COOH in condensed form.
type of strong bond formed between two atoms of the same or different elements; forms when electrons are shared between atoms
bond formed between two amino acids by a dehydration reaction
(also, condensation) reaction that links monomer molecules, releasing a water molecule for each bond formed
long chain of amino acids linked by peptide bonds
functional group composed of a carbon atom double bonded to an oxygen atom singly bonded to a hydroxyl group

{kind=link}