14.1 Overview of the Central Dogma of Information Flow
Elizabeth Dahlhoff
Learning Objectives
By the end of this section, you will be able to do the following:
- Define a gene.
- Describe the central dogma of information flow in biological systems.
- Differentiate between transcription and translation.
Genes Are at the Center of Biological Information Flow
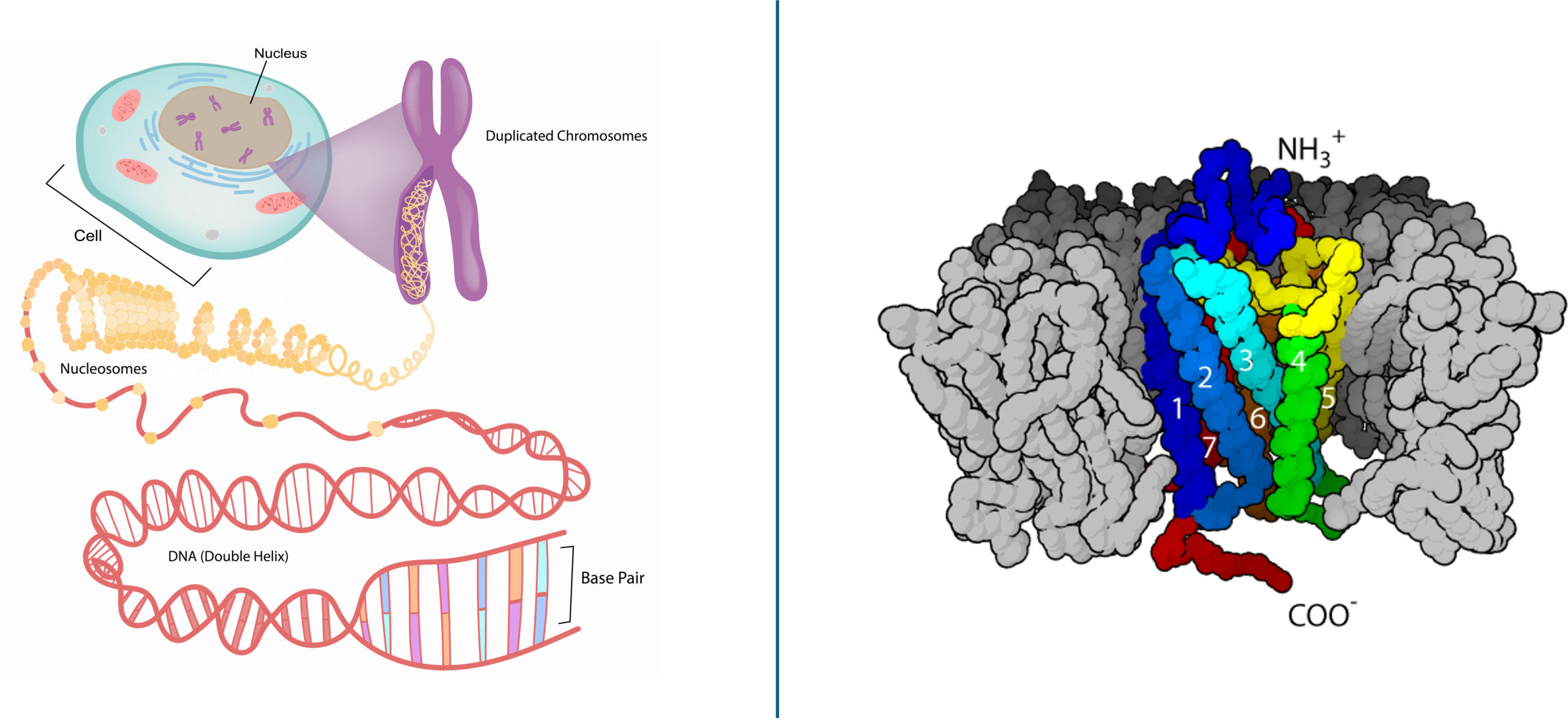
Since Gregor Mendel’s studies of peas over 100 years ago, the definition of a gene has progressed from an abstract unit of heredity to a tangible molecular entity capable of replication, expression, and mutation. Genes are composed of DNA and are linearly arranged on chromosomes. Genes specify sequences of amino acids that are the building blocks of proteins. In turn, proteins are responsible for orchestrating nearly every function of the cell. Both genes and the proteins they encode are absolutely essential to life as we know it.
The Central Dogma: DNA Encodes RNA; RNA Encodes Protein
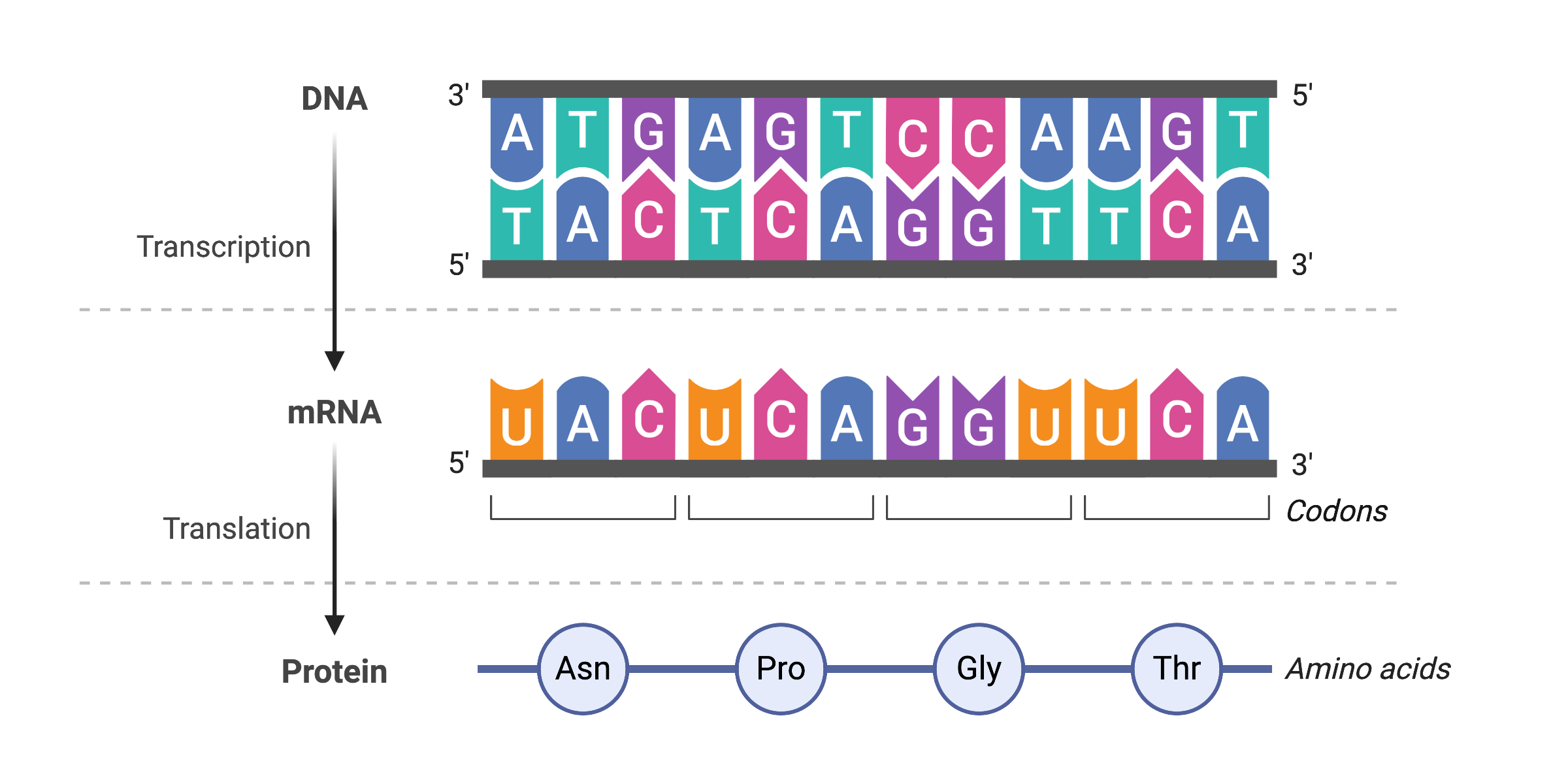
The flow of genetic information in cells from DNA to messenger RNA (mRNA) to protein is described by the central dogma, which states that genes specify the sequence of mRNAs, which in turn specify the sequence of amino acids (polypeptide) making up all proteins. Gene expression is the process of using information from a gene to make a functional product. The best understood process of gene expression is the one by which proteins are made: protein synthesis. Because the information stored in DNA is so central to cellular and thus life function, it makes sense that the cell would make copies of this information (via mRNA) for protein synthesis, while keeping the DNA itself intact and protected.
Transcription, the copying of DNA to mRNA, is relatively straightforward in terms of information flow, with one nucleotide being added to the mRNA strand for every nucleotide read in the DNA strand. The translation of that information to a polypeptide, and ultimately to the synthesis of a mature protein, is a bit more complex. The translation of mRNA to an amino acid chain that makes up a polypeptide is not 1:1; instead, three mRNA nucleotides correspond to one amino acid in the polypeptide sequence. Nucleotides 1 to 3 correspond to amino acid 1, nucleotides 4 to 6 correspond to amino acid 2, and so on. These three-base units are called codons.
Video 14.1.1. From DNA to Protein – 3D by yourgenome
Practice Questions
Figure Descriptions
Licenses and Attributions
Media Attributions
- Amoeba sisters- deconstructed DNA and G-protein-structure
- Central Dogma Sequences © Melissa Hardy is licensed under a CC BY (Attribution) license
