Eukaryotic Transcription
Melissa Hardy
Eukaryotes generally have multiple, linear chromosomes. Eukaryotic mRNAs specify a single protein, as opposed to the mRNA transcribed from operons found in prokaryotes. The structure of a generalized eukaryotic protein-coding gene and its product is shown below.
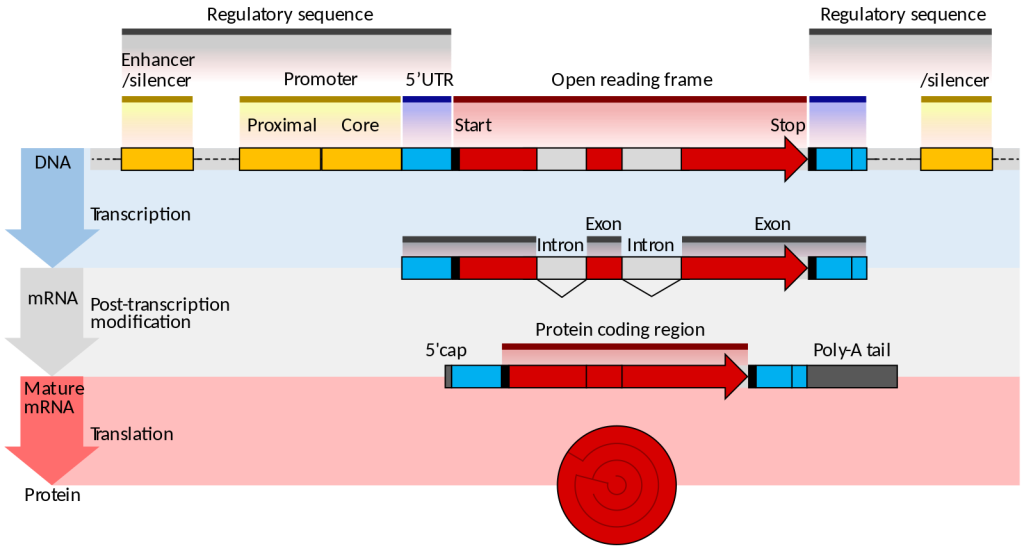
Prokaryotes and eukaryotes perform fundamentally the same process of transcription, with a few key differences. The most important difference between prokaryote and eukaryote transcription is due to the latter’s membrane-bound nucleus and organelles. With the genes bound in a nucleus, the eukaryotic cell must be able to transport its mRNA to the cytoplasm and must protect its mRNA from degrading before it is translated. Eukaryotes also employ three different polymerases that each transcribe a different subset of genes.
| RNA Polymerase | Cellular Compartment | Product of Transcription |
| I | Nucleolus | All rRNAs except 5S rRNA |
| II | Nucleus | All protein-coding nuclear pre-mRNAs and most small nuclear RNAs |
| III | Nucleus | 5S rRNA, tRNAs, and some small nuclear RNAs |
RNA polymerase II is located in the nucleus and synthesizes all protein-coding nuclear pre-mRNAs. Eukaryotic pre-mRNAs undergo extensive processing after transcription but before translation. For clarity, this chapter will use the term “mRNAs” to describe only the mature, processed molecules that are ready to be translated. RNA polymerase II is responsible for transcribing the overwhelming majority of eukaryotic genes.
RNA Polymerase II Promoters and Transcription Factors
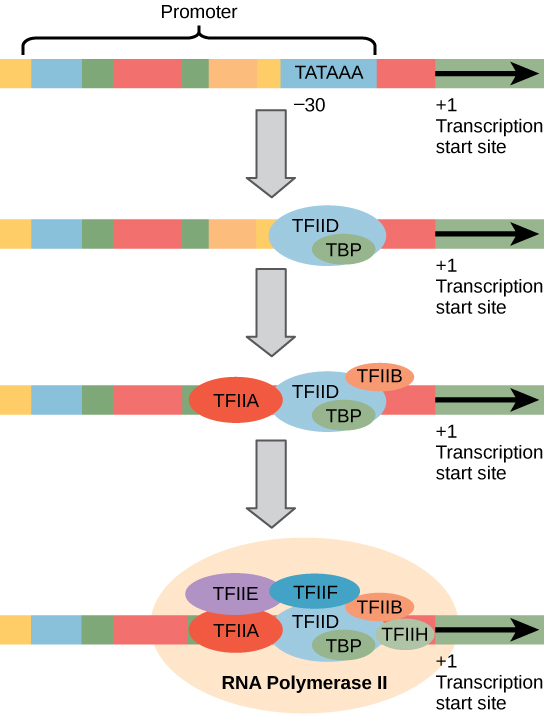
Eukaryotic promoters are much larger and more intricate than prokaryotic promoters. However, both have a sequence similar to the -10 sequence of prokaryotes. In eukaryotes, this sequence is called the TATA box, and has the consensus sequence TATAAA on the coding strand. It is located at -25 to -35 bases relative to the initiation (+1) site.
Like prokaryotic cells, the transcription of genes in eukaryotes requires the action of an RNA polymerase to bind to a DNA sequence upstream of a gene in order to initiate transcription of that gene. However, unlike prokaryotic cells, the eukaryotic RNA polymerase requires other proteins, or transcription factors, to facilitate transcription initiation. RNA polymerase by itself cannot initiate transcription in eukaryotic cells. There are two types of transcription factors that regulate eukaryotic transcription: General (or basal) transcription factors bind to the core promoter region to assist with the binding of RNA polymerase. Specific transcription factors bind to various regions outside of the core promoter region and interact with the proteins at the core promoter to enhance or repress the activity of the polymerase.
Enhancers and Transcription
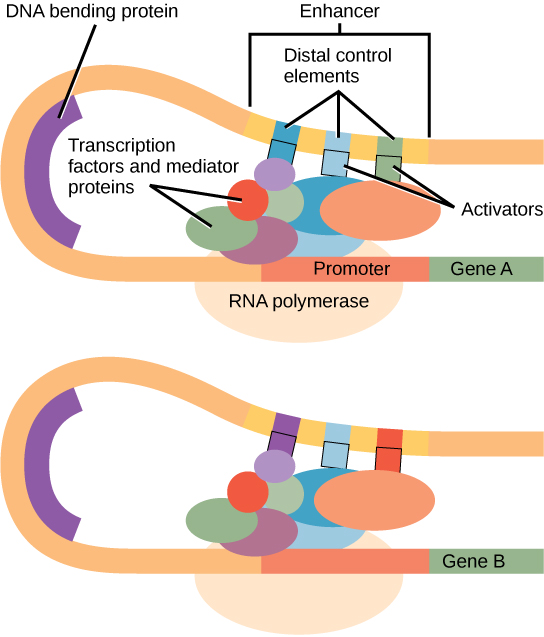
In some eukaryotic genes, there are additional regions that help increase or enhance transcription. These regions, called enhancers or regulatory switches, are not necessarily close to the genes they enhance. They can be located upstream of a gene, within the coding region of the gene, downstream of a gene, and may be thousands of nucleotides away.
Enhancer regions are binding sequences, or sites, for specific transcription factors. When a protein transcription factor binds to its enhancer sequence, the shape of the protein changes, allowing it to interact with proteins at the promoter site. However, since the enhancer region may be distant from the promoter, the DNA must bend to allow the proteins at the two sites to come into physical contact. DNA bending proteins help to bend the DNA and bring the enhancer and promoter regions together. This shape change allows for the interaction of the specific activator proteins bound to the enhancers with the general transcription factors bound to the promoter region and the RNA polymerase.
Eukaryotic Elongation and Termination
Following the formation of the preinitiation complex, the polymerase is released from the promoter, and elongation is allowed to proceed as it does in prokaryotes with the polymerase synthesizing pre-mRNA in the 5′ to 3′ direction. As discussed previously, RNA polymerase II transcribes the major share of eukaryotic genes, so in this section we will focus on how this polymerase accomplishes elongation and termination.
Although the enzymatic process of elongation is essentially the same in eukaryotes and prokaryotes, the DNA template is considerably more complex. When eukaryotic cells are not dividing, their genes exist as a diffuse mass of DNA and proteins called chromatin. The DNA is tightly packaged around charged histone proteins at repeated intervals. These DNA–histone complexes, collectively called nucleosomes, are regularly spaced and include 146 nucleotides of DNA wound around eight histones like thread around a spool.
For polynucleotide synthesis to occur, the transcription machinery needs to move histones out of the way every time it encounters a nucleosome. This is accomplished by a special protein complex called FACT, which stands for “facilitates chromatin transcription.” This complex pulls histones away from the DNA template as the polymerase moves along it. Once the pre-mRNA is synthesized, the FACT complex replaces the histones to recreate the nucleosomes.
The termination of transcription is different for the different polymerases. Unlike in prokaryotes, elongation by RNA polymerase II in eukaryotes takes place 1,000 to 2,000 nucleotides beyond the end of the gene being transcribed. This pre-mRNA tail is subsequently removed by cleavage during mRNA processing. On the other hand, RNA polymerases I and III require termination signals. Genes transcribed by RNA polymerase I contain a specific 18-nucleotide sequence that is recognized by a termination protein. The process of termination in RNA polymerase III involves an mRNA hairpin similar to rho-independent termination of transcription in prokaryotes.
Media Attributions
- Gene_structure_eukaryote_2_annotated.svg © Thomas Shafee is licensed under a CC BY (Attribution) license
- Eukaryote Transcription factors © OpenStax is licensed under a CC BY (Attribution) license
- Enhancers © OpenStax is licensed under a CC BY (Attribution) license

Although there is a large variety, each item of food in the image above ultimately can be linked back to photosynthesis in its own way. Meats and dairy link, because the animals were fed plant-based foods, such as the soybeans that both make up tofu and feed the cows that become beef. The breads, lentils, and rice come largely from starchy grains, which are the seeds of photosynthesis-dependent plants. Even dessert and drinks contain sugars like sucrose, a plant product, a disaccharide, a carbohydrate molecule, which is built directly from photosynthesis. Moreover, less obvious products such as paper goods are generally plant products, and many plastics (abundant as products and packaging) are derived from “algae” (unicellular plant-like organisms, and cyanobacteria). Virtually every spice and flavoring in our meals was produced by a plant as a leaf, root, bark, flower, fruit, or stem. Ultimately, photosynthesis connects to every meal and every food a person consumes.
Codons specify amino acids
Each amino acid is defined by a three-nucleotide sequence called a triplet codon, or simply a codon. Given the different numbers of “letters” in the mRNA and protein “alphabets,” scientists theorized that single amino acids must be represented by combinations of nucleotides. Nucleotide doublets would not be sufficient to specify every amino acid because there are only 16 possible two-nucleotide combinations (42). In contrast, there are 64 possible nucleotide triplets (43), and there are 20 different amino acids encoded. Scientists theorized that amino acids were encoded by nucleotide triplets and that the genetic code was “degenerate.” In other words, a given amino acid could be encoded by more than one nucleotide triplet. This was later confirmed experimentally: Francis Crick and Sydney Brenner used the chemical mutagen proflavin to insert one, two, or three nucleotides into the gene of a virus. When one or two nucleotides were inserted early in the coding sequence, the normal proteins were not produced. When three nucleotides were inserted, the protein was synthesized and functional. This demonstrated that the amino acids must be specified by groups of three nucleotides. These nucleotide triplets are called codons. The insertion of one or two nucleotides completely changed the triplet reading frame, thereby altering the message for every subsequent amino acid. Though insertion of three nucleotides caused an extra amino acid to be inserted during translation, the integrity of the rest of the protein was maintained.
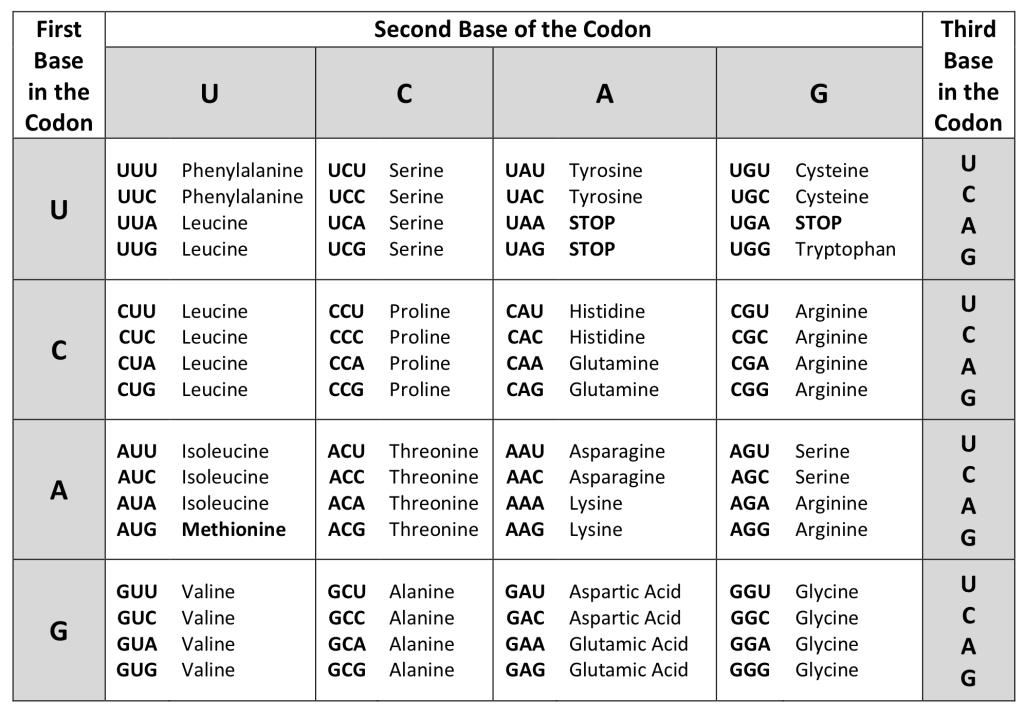
The Genetic Code Is Degenerate
In addition to codons that instruct the addition of a specific amino acid to a polypeptide chain, three of the 64 codons terminate protein synthesis and release the polypeptide from the translation machinery without the attachment of an amino acid. These triplets are called nonsense codons, or stop codons. Another codon, AUG, also has a special function. In addition to specifying the amino acid methionine, it also serves as the start codon to initiate translation. The reading frame for translation is set by the AUG start codon near the 5' end of the mRNA. Following the start codon, the mRNA is read in groups of three until a stop codon is encountered.
The arrangement of the coding table reveals the structure of the code. There are sixteen "blocks" of codons, each specified by the first and second nucleotides of the codons within the block, e.g., the "AC*" block that corresponds to the amino acid threonine (Thr). Some blocks are divided into a pyrimidine half, in which the codon ends with U or C, and a purine half, in which the codon ends with A or G. Some amino acids get a whole block of four codons, like alanine (Ala), threonine (Thr) and proline (Pro). Some get the pyrimidine half of their block, like histidine (His) and asparagine (Asn). Others get the purine half of their block, like glutamate (Glu) and lysine (Lys). Note that some amino acids get a block and a half-block for a total of six codons.
The specification of a single amino acid by multiple similar codons is called "degeneracy." Degeneracy is believed to be a cellular mechanism to reduce the negative impact of random mutations. Codons that specify the same amino acid typically only differ by one nucleotide. In addition, amino acids with chemically similar side chains tend to be encoded by similar codons. For example, aspartate (Asp) and glutamate (Glu), which occupy the GA* block, are both negatively charged. This nuance of the genetic code causes a single-nucleotide substitution mutation to sometimes specify the same amino acid (and therefore have no effect on protein function) or a similar amino acid (increasing the chances for the protein to retain complete or partial function).
The genetic code is nearly universal.
With a few minor exceptions, virtually all species use the same genetic code for protein synthesis. Conservation of codons means that a purified mRNA encoding the globin protein in horses could be transferred to a tulip cell, and the tulip would synthesize horse globin. That there is only one genetic code is powerful evidence that all of life on Earth evolved from a common ancestor, especially considering that there are about 1084 possible combinations of 20 amino acids and 64 triplet codons.

{kind=link}