3.3 Nucleic Acid Structure and Function
Learning Objectives
By the end of this section, you will be able to do the following:
- Describe nucleic acids’ structure.
- Define the functions of the two types of nucleic acids (DNA and RNA).
DNA and RNA
Nucleic acids are the most important macromolecules for the continuity of life. They carry the cell’s genetic blueprint and carry instructions for its functioning.
The two main types of nucleic acids are deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). DNA is the genetic material in all living organisms, ranging from single-celled bacteria to multicellular mammals. It is in the nucleus of eukaryotes, and in the chloroplasts and mitochondria, two membrane-bound organelles. In prokaryotes, the DNA is not enclosed in a membrane-bound organelle.
The other type of nucleic acid, RNA, has many roles in the cell. One type of RNA, called messenger RNA (mRNA) carries information from DNA to ribosomes. Other types of RNA—like ribosomal RNA (rRNA), transfer RNA (tRNA), and microRNA (miRNA)—are involved in protein synthesis and its regulation.
Video 3.3.1. Central Dogma of Biology by BioCASTS
Nucleotides
DNA and RNA are comprised of monomers called nucleotides. The nucleotides combine with each other to form a polynucleotide, DNA or RNA. Three components comprise each nucleotide: a nitrogenous base, a pentose (five-carbon) sugar, and one or more phosphate groups. Each nitrogenous base in a nucleotide is attached to a sugar molecule, which is attached to one or more phosphate groups.
The nitrogenous bases are organic molecules that contain nitrogen. They are bases because they contain an amino group that has the potential of binding an extra hydrogen and thus decreasing the hydrogen ion concentration in its environment, making it more basic. Each nucleotide in DNA contains one of four possible nitrogenous bases: adenine (A), guanine (G) cytosine (C), and thymine (T). Each of these basic carbon-nitrogen rings has different functional groups attached to it. In molecular biology shorthand, we use the symbols A, T, G, C, and U for the nitrogenous bases. DNA contains A, T, G, and C, whereas RNA contains A, U, G, and C.
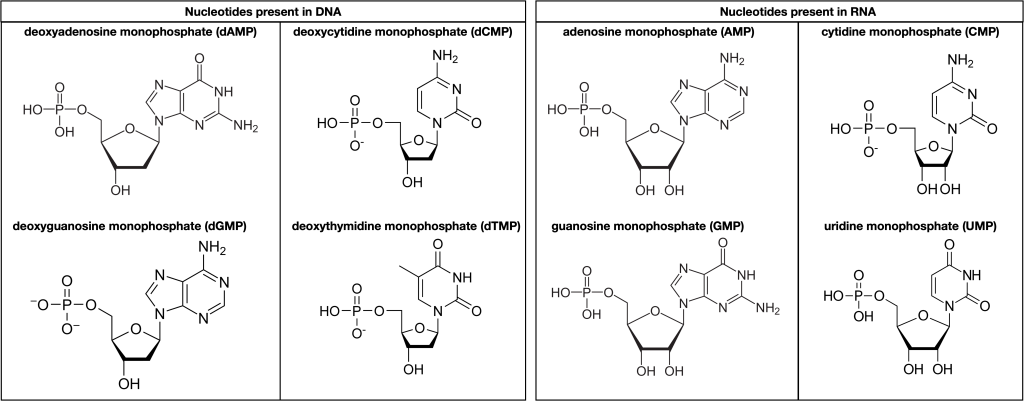
The pentose sugar in DNA is deoxyribose, and in RNA, the sugar is ribose. The difference between the sugars is the presence of the hydroxyl group on the ribose’s second carbon and hydrogen on the deoxyribose’s second carbon. The carbon atoms of the sugar molecule are numbered as 1′, 2′, 3′, 4′, and 5′ (1′ is read as “one prime”).
Polynucleotides
A phosphate residue connects the 5′ carbon of one sugar to the 3′ carbon of the sugar of the next nucleotide, which a covalent bond called a phosphodiester bond. A polynucleotide may have thousands or even millions of phosphodiester linkages.
The Double Helix
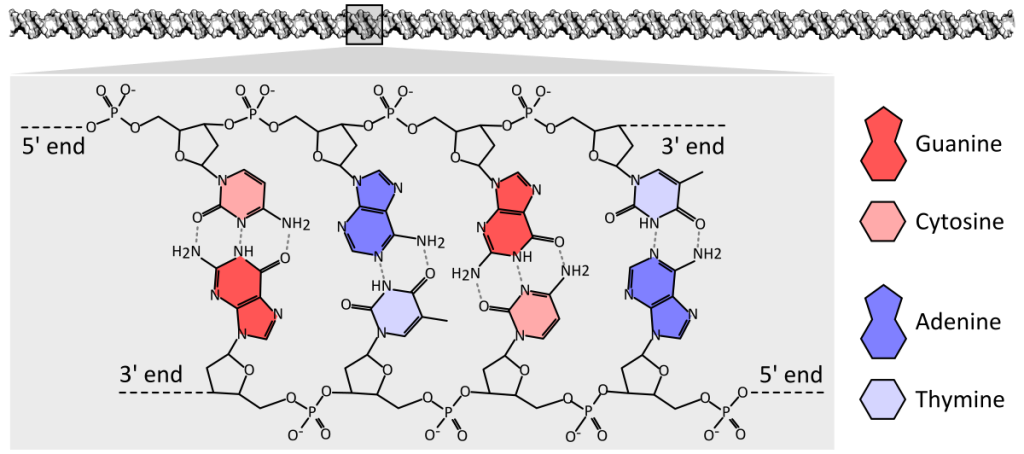
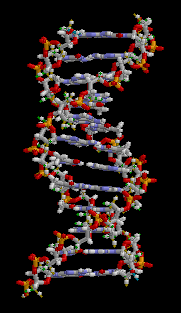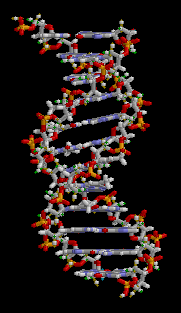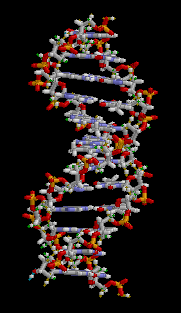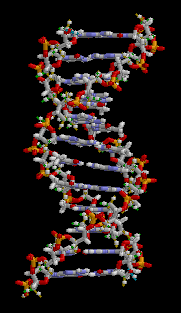
DNA has a double-helix structure. The sugar and phosphate lie on the outside of the helix, forming the DNA’s backbone. The nitrogenous bases are stacked in the interior, like a pair of staircase steps. Hydrogen bonds bind the pairs to each other.
Base pairing is specific. A can pair with T, and G can pair with C. This is the base complementary rule. In other words, the DNA strands are complementary to each other. If the sequence of one strand is 5′-AATTGGCC-3′, the complementary strand would have the sequence 3′-TTAACCGG-5′.
Video 3.3.2. The Structure of DNA by MITx Bio
Practice Questions
Glossary
deoxyribonucleic acid (DNA)
double-helical molecule that carries the cell’s hereditary information
ribonucleic acid (RNA)
single-stranded, often internally base paired, molecule that is involved in protein synthesis
nucleotide
monomer of nucleic acids; contains a pentose sugar, one or more phosphate groups, and a nitrogenous base
Figure Descriptions
Figure 3.3.1. The image is a detailed schematic representation of nucleotide components and their structures. At the top, there are two sections labeled “Pyrimidines” and “Purines” with illustrations of their chemical structures. The pyrimidines section includes structures for Cytosine, Thymine, and Uracil, each labeled with their molecular structure. The purines section contains Adenine and Guanine, also showing their molecular structure. Below these sections is a central box labeled “Base” containing a generalized structure for a nitrogenous base linking it to a pentose sugar, labeled as “Deoxyribose or ribose sugar.” This sugar structure includes both deoxyribose and ribose configurations, highlighting differences at the 2′ position. To the left, a small box labeled “Phosphate” shows a phosphate group structure as part of the nucleotide. At the bottom, two separate boxes depict the structural differences between “Deoxyribose (in DNA)” and “Ribose (in RNA)” with emphasis on the 2′ carbon. On the right, there is a combination structure showing how the phosphate, sugar, and base are connected. It highlights the 5′, 3′, and 2′ carbon positions in red, with the sugar being a part of a larger nucleotide chain. [Return to Figure 3.3.1]
Figure 3.3.2. Left panel: “Nucleotides present in DNA.” Four deoxyribonucleotides are shown, each with a phosphate group on the left, a five-carbon deoxyribose sugar in the center (highlighted with thicker bond lines), and a nitrogenous base on the right. From top to bottom they are: Deoxyadenosine monophosphate (dAMP) – adenine base; Deoxycytidine monophosphate (dCMP) – cytosine base; Deoxyguanosine monophosphate (dGMP) – guanine base; Deoxythymidine monophosphate (dTMP) – thymine base. Each sugar lacks the 2′-hydroxyl group characteristic of ribose. Right panel: “Nucleotides present in RNA.” Four ribonucleotides are shown with the same general layout, but their sugars retain the 2′-hydroxyl group. From top to bottom they are: Adenosine monophosphate (AMP) – adenine base. Cytidine monophosphate (CMP) – cytosine base. Guanosine monophosphate (GMP) – guanine base. Uridine monophosphate (UMP) – uracil base (RNA’s substitute for thymine). Across both panels, the diagram highlights that every nucleotide consists of: one phosphate group (negatively charged), one pentose sugar (deoxyribose in DNA, ribose in RNA), and one nitrogen-containing base (A, C, G, T, or U). No color is used; structural details are conveyed with black lines and labels. [Return to Figure 3.3.2]
Figure 3.3.3. This diagram presents a four-base-pair fragment of double-stranded DNA displayed horizontally, with the antiparallel strands running left-to-right along the top and right-to-left along the bottom; each strand shows a repeating sugar-phosphate backbone (black pentagons and circles) and, extending inward, color-coded nitrogenous bases—adenine (red), thymine (pink), cytosine (dark blue), and guanine (light blue). Adenine on the upper strand forms two dashed hydrogen-bond lines with thymine on the lower strand, while cytosine forms three dashed hydrogen-bond lines with guanine, clearly illustrating the A–T and C–G pairing rules and the difference in hydrogen-bond number. Labels identify the 5′ and 3′ ends on both strands to emphasize their antiparallel orientation, and a small legend at the right matches each base’s color and shape to its name. [Return to Figure 3.3.3]
Figure 3.3.4. The looping GIF depicts a short fragment of double-stranded DNA rendered as a ball-and-stick model on a black background; as the molecule slowly rotates about its vertical axis, a right-handed double helix of roughly a dozen base pairs becomes visible, with two spiraling sugar-phosphate backbones on the outside—each alternating gray-and-white five-carbon sugar rings and orange-red phosphate groups—and flat, ladder-like rungs of complementary nitrogenous base pairs in blue and green tones spanning between them. The continuous rotation highlights the wider major groove and narrower minor groove, shows how the backbones shield the interior bases, and emphasizes the repeating twist along the molecule’s length, conveying the same instructional detail without narration or reliance on color alone. [Return to Figure 3.3.4]
Licenses and Attributions
“3.3 Nucleic Acid Structure Function” is adapted from “3.5 Nucleic Acids” by Mary Ann Clark, Matthew Douglas, and Jung Choi for OpenStax Biology 2e under CC-BY 4.0. “3.3 Nucleic Acid Structure Function” is licensed under CC-BY-NC 4.0.
Media Attributions
- Nucleotides © Melissa Hardy is licensed under a Public Domain license
- DNA chemical structure © Thomas Shafee is licensed under a CC BY (Attribution) license
- DNA animation © Brian0918 is licensed under a Public Domain license
double-helical molecule that carries the cell's hereditary information
single-stranded, often internally base paired, molecule that is involved in protein synthesis
RNA that carries information from DNA to ribosomes during protein synthesis
smallest unit of larger molecules that are polymers
monomer of nucleic acids; contains a pentose sugar, one or more phosphate groups, and a nitrogenous base
long chain of nucleotides

{kind=link}
{kind=link}