19 How Does Generative AI Work?
Overview
In this chapter, you’ll learn how generative artificial intelligence (AI) technology works, particularly products like ChatGPT and other large language models (LLMs). You will consider the potential opportunities and risks that come with using AI tools for the composing and communication process, including an expanded understanding of the rhetorical situation.
Learning Outcomes
By the end of this chapter, you’ll be able to:
- Explain how generative AI technology works as a model of language
- Differentiate the human-centered model of writing from the machine model of writing
- Evaluate the benefits and drawbacks of generative AI for the creation of language
Artificial Intelligence and Large Language Models
Over the past few years, we have seen the widespread adoption of artificial intelligence technologies: programs like ChatGPT, Grammarly, or Dall-E, as well as tools that have been added to existing social media platforms and systems like Instagram and Canva. Even as I am writing this chapter in Google Docs, the integrated AI assistant is making suggestions about how this sentence should be written. These technologies are changing the ways that we work, create, and even how we think — just like how any new technology has the power to change society and our lives. This change is neither wholly good nor bad, but it’s essential that we try to understand how it is changing things.
When we hear the phrase “artificial intelligence,” we might think of robots and androids from science fiction. Characters like Data from Star Trek or Samantha from Her question what it means to be alive and to be human, and their stories shape our understanding of the AI technologies that we are encountering in the present. But be careful: these stories tend to anthropomorphize their AI characters, making them appear to be indistinguishable from humans, with their own agency, thoughts, and desires. This is not true of AI in the present; text-generators like ChatGPT cannot truly “think”, even though we can have conversations with them. Similarly, image generators like Dall-E do not have any real artistic intention behind what they create. In order for us to truly understand AI’s potential uses and risks, we have to establish a clearer understanding of how it works.

The artificial intelligence technologies that we are most familiar with right now are forms of generative AI, which creates new content based on existing data. More specifically, the field of rhetoric has been interested in AI text generation that is produced by large language models. They function by taking examples of language created by others and using them as a basis for their responses. We can therefore approach an understanding of LLMs by breaking down the processes they use and then the data they draw from.
While earlier models of text generation leaned on grammatical rules, current models are more speculative, predicting the next word in a sequence based on patterns in its dataset. For text generation, large language models train on massive datasets found primarily via the Internet using machine learning techniques; they are then subjected to fine-tuning and reinforcement learning through human feedback (RLHF) to refine their output. Over the last ten years — particularly since late 2017 — these techniques have catapulted the field of generative AI, producing so-called “foundation models” that can generate text, image, video or sound across generalized contexts.
Developments have been so dramatic that in technology news, AI podcasts, and social media, the narrative on generative AI is about our relentless march toward artificial general intelligence (AGI). Despite the distortion from overblown claims, no research field has promised so much and delivered so little as AI. When the hype is separated from reality, these remain extremely difficult technologies to grasp: even AI scientists and engineers do not completely understand the full potential, limitations, or implications of AI. Below, we outline briefly how generative AI works for text generation and what variables might shape the future of these technologies. AI’s dominant role in text generation right now means that soon, even basic engagement with word processing might require a basic understanding of how contemporary LLMs work.
How Do Large Language Models Work?
One way to appreciate how LLMs work is to compare and contrast their processes with the methods a human uses when drafting a college essay.
Human-Centered Model of Writing

In first-year writing programs, students learn the writing process, which often includes some variation of the following:
- Free-write and brainstorm about a topic.
- Research and take notes.
- Analyze and synthesize research and personal observations.
- Draft a coherent essay based on the notes.
- Get feedback.
- Revise and copyedit.
- Publish and submit the paper.
It’s worth noting that the first stage is often one of the most important: writers initially explore their own relationship to the topic. When doing so, they draw on prior experiences and beliefs. These include worldviews and principles that shape a writer’s understanding of what matters and what voices or opinions seem most credible.
Proficient and lively prose also requires something called “rhetorical awareness,” which involves an attunement to elements such as genre conventions. When shifting to the drafting stage, a writer is faced with many questions: “How do I know where to start?”; “What is the purpose of my paper?”; “What research or justification should I include?”; “How do I include my personal perspective?”; “How do I tailor my writing to fit my intended audience?” These techniques and questions are a large portion of what first-year college writing tends to focus on. They’re what help academic writers gain skill and confidence while finding their own voice.
In short, a human-centered writing model involves a complex combination of the writer’s voice (their worldview and beliefs, along with their experiences and observations), other voices or perspectives (through research and feedback), and basic pattern recognition (studying examples of other essays or using templates). It’s highly interactive and remains “social” throughout.
Machine Model of Writing

What happens when a student prompts an LLM, such as ChatGPT, to generate an essay? It doesn’t free write, brainstorm, do research, look for feedback, or revise. Prior beliefs are irrelevant. It doesn’t have a worldview. It has no experience. Instead, something very different happens to generate the output.
LLMs rely almost entirely on the pattern recognition step mentioned above but in a vastly accelerated and amplified way. An LLM can easily produce an essay that, at a glance, looks like a proficient college-level essay because it excels at things like recognizing and replicating genre conventions. How does it do this?
Examining the process of training an LLM is helpful for understanding why they perform so well at tasks that require pattern recognition. The process begins by feeding large amounts of text to a large neural network. OpenAI’s well-known chatbot, ChatGPT, was trained on internet archives including repositories of scholarly essays and digitized books, as well as communal sources like Reddit and Wikipedia.
The process of translating human language found in these archives into code that machines can analyze and manipulate is called natural language processing (NLP). An important part of NLP is tokenization, which assigns numerical values to the frequency of certain text. Here’s a video that offers an excellent introduction to tokenization (~9 mins):
Basically, tokenization represents words as numbers. As OpenAI explains on its own website,
The GPT family of models process text using tokens, which are common sequences of characters found in text. The models understand the statistical relationships between these tokens and excel at producing the next token in a sequence of tokens (“Tokenizer”).
OpenAI allows you to plug in your own text (“Tokenizer” [Website]) to see how it’s represented by tokens. Here’s a screenshot of Tokenizer’s results for the sentence: “The cat jumped over the moon!”
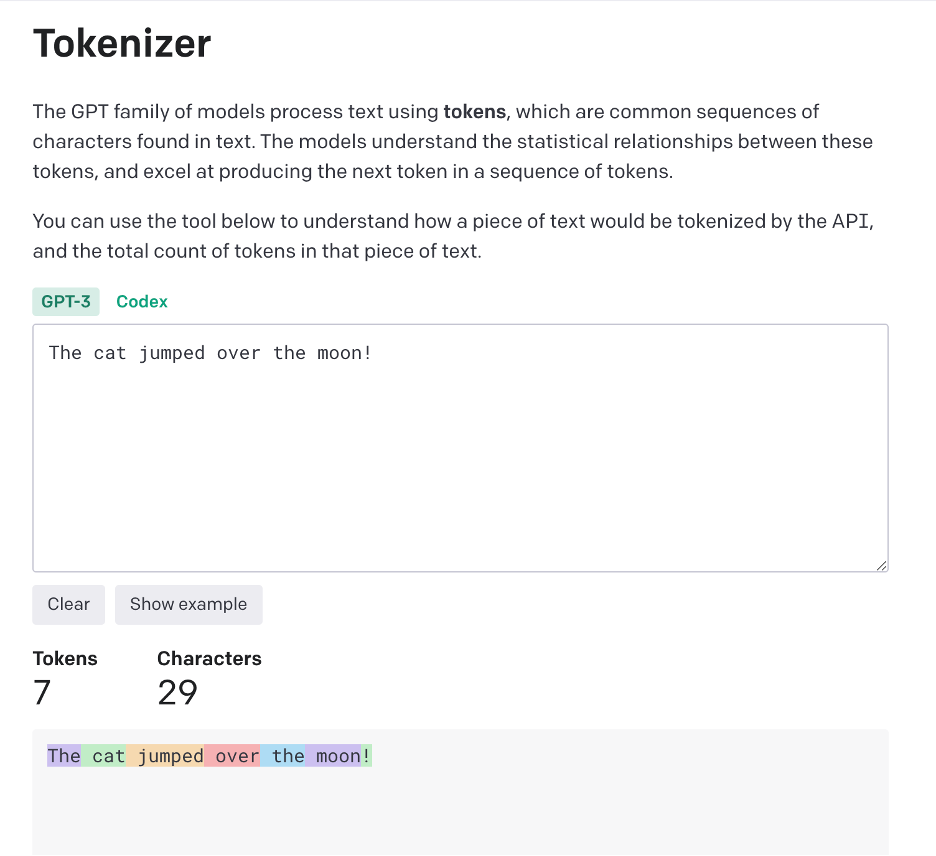
Figure 19.1. Screenshot of how the sentence “The cat jumped over the moon!” is represented as tokens. Tokenizer can be access from OpenAI’s own website. [Image Description]
Note how each common word is represented by a single token, and the exclamation mark also counts as its own token.
After numbers are assigned to each word, the next stage is to figure out what words belong together. This process, called embedding, uses the distribution of words in a text to determine meaning. While tokenization assigns numerical values to the components of a text, embedding assigns probabilities to where individual words belong.
This embedding method takes advantage of the fact that words can generate meaning by mere association.
Here’s an example of how the association of an unknown word within a string of recognizable statements can communicate meaning to the reader:
- Ongchoi is delicious sauteed with garlic.
- Ongchoi is superb over rice.
- …ongchoi leaves with salty sauces…
Suppose that you had seen many of these context words in other contexts:
- …spinach sauteed with garlic over rice…
- …chard stems and leaves are delicious…
- …collard greens and other salty leafy greens.
After reading this series of statements, many readers will have some basic understanding of what the term “ongchoi” might mean, even if they had not previously heard of it.
The fact that “ongchoi” is used alongside words like “rice” and “garlic” or “delicious” and “salty,” as do words like “spinach,” “chard,” and “collard greens” might suggest that ongchoi is a leafy green similar to these other examples. We can come to the same conclusion computationally by counting words in the context of usages of “ongchoi”.
Without knowing anything about the meaning of “ongchoi” prior to the example above, a reader can infer at least some of its meaning because of how it’s associated with other words. Context determines meaning and NLP embedding leverages this phenomenon (Jurafsky and Martin).
When I input a string of characters into ChatGPT, it simply generates an output by predicting the next token. That’s it!
Dig Deeper
The New York Times article “Let Us Show You How GPT Works — Using Jane Austen” [Website] by Aatish Bhatia shows us what it looks like when you gradually train small AI text generation systems, called large language models, in the style of Harry Potter, Star Trek: The Next Generation, Moby Dick, Shakespeare plays, or Jane Austen novels.
Let’s take a look at the Harry Potter version. Before training, the user types in “Hermione raised her wand,” and the language model continues “.Pfn“tkf^2JXR454tn7T23ZgE——yEIé\mmf’jHgz/yW;>>QQi0/PXH;ab:XV>”?y1D^^n—RU0SVGRW?c>HqddZZj:”
That’s its random guess as to what comes next.
Then it goes through several rounds of training, ingesting text from Harry Potter and adjusting its internal prediction numbers to match patterns in that text.
Eventually, when the user writes “Hermione raised her wand,” the model continues in a recognizably “Harry Potter-ish” way:
“Professor Dumbledore never mimmed Harry. He looked back at the room, but they didn’t seem pretend to blame Umbridge in the Ministry. He had taken a human homework, who was glad he had not been in a nightmare bad cloak.”
Yep, it’s echoing the books and movies with main characters’ names, a reference to the Ministry of Magic, and “nightmare bad” cloaks that suggest magic and evil. But there’s no such word as “mimmed.” And why does homework care if some person is wearing a cloak? This is where I start to chuckle.
If you kept training a system like this, it would eventually give you a sentence that might be hard to tell apart from Harry Potter author J.K. Rowling’s sentences. But the system would still be matching patterns and predicting next words.
So next time you see AI produce a smooth, polished sentence that sounds just like sophisticated academic writing, remember the “Harry Potter-ish” gobbledygook. The lights might be on, but nobody’s home. Check whether the text is empty or wrong. If it does make sense and matches reality, remember, that’s partly luck. The system makes up true sentences the same way it makes up nonsense.
So, should we trust it? No.
Conclusion
It might seem like learning how LLMs work is more appropriate for a computer science class than a rhetoric class. However, the important point here is that while an LLM’s output might appear to be intelligent, it is only mimicking patterns of language use that it has been trained on. Contrary to what we have seen in science fiction, generative AI does not possess actual intelligence or intention — which is why a human-centered model of writing is still needed!
Test Your Knowledge
Activities
Ask an LLM (like ChatGPT) a question about a subject that you know a lot about (such as a book, show, or hobby). Start with some general questions, and then get more specific. Assess the extent to which the answers are correct (remember — you’re the “expert” in this case). When do the answers start getting less precise and credible? Does the LLM acknowledge the limits of its information, or does it start making up answers? What does this tell you about the extent to which you should trust LLMs as a source for information?
Works Cited
Bhatia, Aatish. “Let Us Show You How GPT Works — Using Jane Austen.” The New York Times, 27 Apr. 2023, www.nytimes.com/interactive/2023/04/26/upshot/gpt-from-scratch.html?smid=nytcore-ios-share&referringSource=articleShare.
Gladd, Joel. “Tokenization.” Long English 102, College of Western Idaho, cwi.pressbooks.pub/longenglish102/chapter/how-llms-work/.
Google for Developers. “Machine Learning Foundations: Ep #8 – Tokenization for Natural Language Processing.” YouTube, 16 June 2020, www.youtube.com/watch?v=f5YJA5mQD5c. Accessed 30 June 2025.
Jurafsky, D., and J. Martin. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition. 3rd ed., Stanford, 2023, web.stanford.edu/~jurafsky/slp3/ed3book_jan72023.pdf.
Knowles, Alan. “Tokenized Sentence.” AI Literacy: An Open Educational Resource, Colorado State University, wac.colostate.edu/repository/collections/textgened/ai-literacy/rhetorical-analysis-of-predictive-llms/.
“Notebook.” First Year Seminar: Research & Information Literacy, CUNY, pressbooks.cuny.edu/lagccfys/chapter/writing-assignment-strategies/.
OpenAI. “OpenAI API.” Platform.openai.com, platform.openai.com/tokenizer.
“Robot Softbank Pimienta.” Pixabay, 12 Oct. 2016, pixabay.com/es/photos/robot-softbank-pimienta-tableta-1695653/.
Image Descriptions
Figure 19.1. A screenshot from a webpage titled “Tokenizer” explains: “The GPT family of models process text using tokens, which are common sequences of characters found in text. The models understand the statistical relationships between these tokens, and excel at producing the next token in a sequence of tokens. You can use the tool below to understand how a piece of text would be tokenized by the API, and the total count of tokens in that piece of text.” A text box contains the sentence “The cat jumped over the moon!” Buttons read “Clear” and “Show example”. A model toggle shows GPT-3 (selected) and Codex. Below, counters show Tokens: 7 and Characters: 29. A colored bar visualizes each token as separate segments labeled “The”(in purple), “ cat” (in green), “ jumped” (in orange), “ over” (in pink), “ the” (in blue), “ moon” (in purple), and “ !” (in green), illustrating how the sentence is tokenized on OpenAI’s site. [Return to Figure 19.1]
Attributions
This chapter was written and remixed by Phil Choong.
The “Artificial Intelligence and Large Language Models” section was adapted from “An Introduction to Teaching with Generative AI Technologies” by Tim Laquintano, Carly Schnitzler, and Annette Vee and is licensed under CC BY-NC.
The “How Do Large Language Models Work?” section was adapted from “How Do Large Language Models (LLMs) like ChatGPT Work?” by Joel Gladd and is licensed under CC BY-NC-SA 4.0.
The “Dig Deeper” section was adapted from “AI Copies Patterns; It Doesn’t Think” by Anna Mills and is licensed under CC BY-NC 4.0.
Media Attributions
- Robot Softbank Pimienta © imjanuary is licensed under a Public Domain license
- Notebook is licensed under a CC BY-SA (Attribution ShareAlike) license
- Tokenized Sentence © Alan Knowles is licensed under a CC BY-NC (Attribution NonCommercial) license
- Tokenization © Joel Gladd is licensed under a CC BY-NC-SA (Attribution NonCommercial ShareAlike) license
